
นักวิทยาศาสตร์ข้อมูล (Data Scientists) ใช้เวลามากถึง 80% ในการทำความสะอาดข้อมูล (Data Cleaning) เพื่อเตรียมความพร้อมสำหรับการวิเคราะห์ การสร้างแบบจำลองทางสถิติ และการทำ Machine Learning ซึ่งจะเห็นได้ว่าการทำความสะอาดข้อมูลเป็นขั้นตอนที่ใช้เวลานานและเป็นพื้นฐานสำคัญก่อนที่จะเริ่มการวิเคราะห์หรือการสร้าง Machine Learning การที่จะทำให้ Machine Learning ประสบความสำเร็จได้นั้น จำเป็นต้องมีข้อมูลที่มีคุณภาพ ดังนั้น บทความนี้จะพาไปทำความเข้าใจว่า Data Cleasning และ Data Cleaning คืออะไร และต่างกันอย่างไร ขั้นตอนในการทำ และทำไมมันจึงมีความสำคัญต่อความสำเร็จของการทำ Machine Learning
Data Cleansing และ Data Cleaning คืออะไร
Data Cleansing หรือการทำความสะอาดข้อมูลอย่างละเอียด คือ การทำให้ข้อมูลมีคุณภาพและเชื่อถือได้ในระดับสูงกว่า ซึ่งรวมถึงการลบข้อมูลที่ไม่จำเป็น การทำให้ข้อมูลเป็นมาตรฐานเดียวกัน และการปรับปรุงข้อมูลในระยะยาว
Data Cleaning หรือการทำความสะอาดข้อมูล เป็นกระบวนการในการจัดการข้อมูลดิบ (raw data) ที่มีปัญหาหรือข้อผิดพลาด เช่น ข้อมูลที่ขาดหาย ข้อมูลที่ซ้ำซ้อน หรือข้อมูลที่มีรูปแบบไม่สอดคล้องกัน เป้าหมายของการทำ Data Cleaning คือการทำให้ข้อมูลมีความสมบูรณ์ ถูกต้อง และพร้อมสำหรับการวิเคราะห์หรือการใช้ในโมเดล Machine Learning
การทำ Data Cleansing และ Data Cleaning เป็นขั้นตอนที่สำคัญเพราะข้อมูลที่ไม่ได้รับการทำความสะอาดอาจมีผลกระทบต่อความแม่นยำของโมเดล ทำให้เกิดข้อผิดพลาดในการทำนาย และลดความน่าเชื่อถือของการตัดสินใจทางธุรกิจ นอกจากนี้ การทำ Data Cleansing และ Data Cleaning ยังช่วยเพิ่มคุณภาพของข้อมูล ซึ่งจะส่งผลให้การวิเคราะห์และการพัฒนาระบบ Machine Learning มีประสิทธิภาพมากยิ่งขึ้น
Data Cleansing และ Data Cleaning ต่างกันอย่างไร
Data Cleaning มักเน้นที่การแก้ไขข้อผิดพลาดที่เห็นได้ชัดในข้อมูล เน้นที่การแก้ไขปัญหาที่เกิดขึ้นในปัจจุบัน ขณะที่ Data Cleansing มีขอบเขตกว้างกว่าและรวมถึงการจัดการข้อมูลอย่างต่อเนื่องเพื่อรักษาคุณภาพของข้อมูล มุ่งเน้นที่การรักษาคุณภาพของข้อมูลในระยะยาว
ทำไม Data Cleansing ถึงเป็นหัวใจของการทำ Machine Learning ที่มีประสิทธิภาพ
การทำ Data Cleansing จึงเป็นหัวใจสำคัญที่ช่วยให้การทำ Machine Learning ประสบความสำเร็จ และเป็นขั้นตอนที่ไม่ควรมองข้ามในการพัฒนาระบบที่มีประสิทธิภาพและแม่นยำ
ตัวอย่างเหตุผลที่ Data Cleansing สำคัญต่อ Machine Learning มีดังนี้
ความแม่นยำของโมเดล:
ข้อมูลที่ไม่ถูกต้อง เช่น ข้อมูลซ้ำ ข้อมูลขาดหาย หรือมีรูปแบบที่ผิดปกติ จะส่งผลให้โมเดลเรียนรู้รูปแบบที่ผิดพลาดและให้ผลลัพธ์ที่ไม่ถูกต้องตามความเป็นจริง
การลดความซับซ้อน
การทำ Data Cleansing จะช่วยลดความซับซ้อนของข้อมูล ทำให้โมเดลสามารถเรียนรู้รูปแบบได้ง่ายขึ้น และช่วยลดเวลาในการฝึกสอนโมเดล
การเพิ่มประสิทธิภาพของโมเดล
ข้อมูลที่สะอาดจะช่วยให้โมเดลมีความสามารถในการทำนายหรือจำแนกข้อมูลใหม่ได้อย่างแม่นยำมากขึ้น
การป้องกันการ Overfitting
การมีข้อมูลที่ผิดปกติหรือ Noise ในข้อมูล อาจทำให้โมเดล Overfitting หรือเรียนรู้ข้อมูลฝึกสอนได้ดีเกินไปจนไม่สามารถนำไปใช้กับข้อมูลใหม่ได้ดี
การสร้างความน่าเชื่อถือ
โมเดลที่สร้างจากข้อมูลที่สะอาดจะได้รับความน่าเชื่อถือมากกว่าโมเดลที่สร้างจากข้อมูลที่ไม่ถูกต้อง
ขั้นตอนการทำงานของ Machine Learning
ขั้นตอนการทำงานของ Machine Learning (Machine Learning Workflow) โดยแบ่งออกเป็น 3 ส่วนหลัก ได้แก่ Data Processing, Modelling และ Deployment ซึ่งมีการเชื่อมต่อกันอย่างต่อเนื่องเพื่อสร้างโมเดล Machine Learning ที่มีประสิทธิภาพ
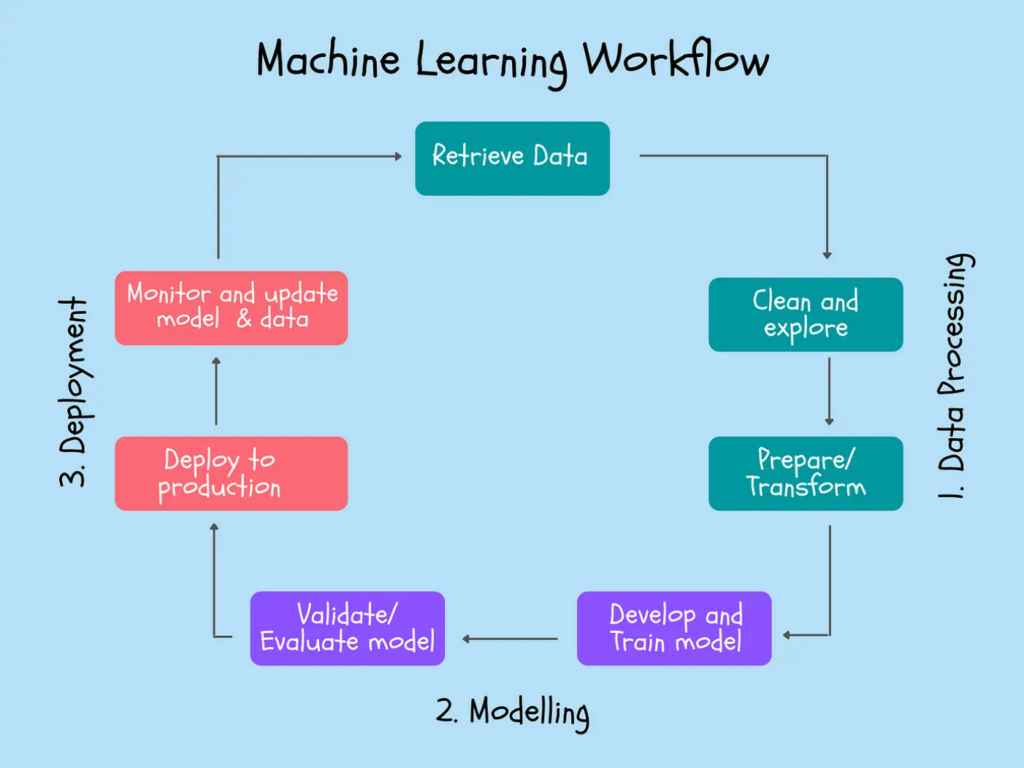
1. Data Processing
- Retrieve Data: ขั้นตอนแรกคือการรวบรวมข้อมูลจากแหล่งต่างๆ ไม่ว่าจะเป็นฐานข้อมูล, APIs หรือแหล่งข้อมูลภายนอกอื่นๆ
- Clean and Explore: ขั้นตอนนี้เป็นขั้นตอนสำคัญมาก ซึ่งก็คือการทำ Data Cleansing ข้อมูลที่รวบรวมมาอาจจะมีความไม่สมบูรณ์, ความผิดพลาด, หรือมีข้อมูลซ้ำซ้อน การทำ Data Cleansing จึงเป็นกระบวนการในการกำจัดข้อมูลที่ไม่ถูกต้องหรือไม่สมบูรณ์ และเตรียมข้อมูลให้พร้อมสำหรับการวิเคราะห์ การทำความสะอาดข้อมูลจะช่วยให้มั่นใจได้ว่าข้อมูลที่นำมาใช้สร้างโมเดลจะมีคุณภาพและเชื่อถือได้
- Prepare/Transform: หลังจากทำ Data Cleansing แล้ว จะต้องแปลงข้อมูลให้อยู่ในรูปแบบที่เหมาะสมสำหรับการนำไปใช้ในการสร้างโมเดล เช่น การแปลงข้อมูลจากรูปแบบข้อความเป็นตัวเลข การสร้างฟีเจอร์ใหม่ หรือการจัดการกับ Missing Data
2. Modelling
- Develop and Train Model: เมื่อข้อมูลพร้อมแล้ว จะเข้าสู่ขั้นตอนการพัฒนาและฝึกอบรมโมเดล Machine Learning โดยใช้ข้อมูลที่ผ่านการ Clean และ Transform มาแล้ว
- Validate/Evaluate Model: เมื่อโมเดลถูกพัฒนาขึ้น จะต้องมีการประเมินและตรวจสอบความแม่นยำของโมเดล หากผลลัพธ์ไม่ดีพอ อาจต้องกลับไปปรับปรุงข้อมูลหรือโมเดลใหม่
3. Deployment
- Deploy to Production: เมื่อโมเดลได้รับการตรวจสอบและผ่านการประเมินเรียบร้อยแล้ว ก็จะนำโมเดลไปใช้งานในระบบจริง
- Monitor and Update Model & Data: หลังจากโมเดลถูกนำไปใช้งานแล้ว จะต้องมีการติดตามผลและปรับปรุงโมเดลหรือข้อมูลให้เหมาะสมกับสภาพแวดล้อมใหม่ๆ ที่เปลี่ยนแปลงไป
การทำ Data Cleansing เป็นขั้นตอนที่มีความสำคัญอย่างมากในกระบวนการ Machine Learning เนื่องจากเป็นการเตรียมข้อมูลให้พร้อมใช้งาน ข้อมูลที่ถูก Clean แล้วจะช่วยให้โมเดล Machine Learning มีความแม่นยำและมีประสิทธิภาพมากยิ่งขึ้น การข้ามขั้นตอนนี้หรือทำอย่างไม่ละเอียดอาจส่งผลให้โมเดลที่พัฒนาขึ้นมีข้อผิดพลาดและไม่น่าเชื่อถือในที่สุด
แนะนำ 7 ขั้นตอนการทำ Data Cleansing ก่อนเริ่มทำ Machine Learning
การทำ Data Cleansing เป็นขั้นตอนสำคัญที่ขาดไม่ได้ก่อนนำข้อมูลไปสร้างโมเดล Machine Learning เพื่อให้ได้ผลลัพธ์ที่แม่นยำและน่าเชื่อถือ ขั้นตอนโดยทั่วไปมีดังนี้
1. ตรวจสอบความสมบูรณ์ของข้อมูล (Completeness)
- ตรวจสอบค่าว่าง: หาข้อมูลที่ขาดหายไปหรือมีค่าว่าง
- จัดการกับค่าว่าง: ตัดสินใจว่าจะเติมค่า (imputation) ลบข้อมูลออก หรือใช้เทคนิคอื่นๆ
2. ตรวจสอบความถูกต้องของข้อมูล (Accuracy)
- ตรวจสอบความเป็นไปได้: ตรวจสอบว่าข้อมูลมีความเป็นไปได้ เช่น อายุเป็นบวก น้ำหนักเป็นบวก
- ตรวจสอบความสอดคล้อง: ตรวจสอบว่าข้อมูลสอดคล้องกับความเป็นจริง เช่น วันเกิดต้องมาก่อนวันที่ปัจจุบัน
3. ตรวจสอบความสอดคล้องของข้อมูล (Consistency)
- ตรวจสอบหน่วยวัด: ตรวจสอบให้แน่ใจว่าหน่วยวัดของข้อมูลเป็นไปในทิศทางเดียวกัน
- ตรวจสอบรูปแบบ: ตรวจสอบให้แน่ใจว่าข้อมูลอยู่ในรูปแบบที่ถูกต้อง เช่น ตัวเลข, ข้อความ
4. กำจัดข้อมูลซ้ำ (Duplicates)
- หาข้อมูลซ้ำ: ใช้เทคนิคการเปรียบเทียบค่าเพื่อหาข้อมูลที่ซ้ำกัน
- ลบข้อมูลซ้ำ: ลบข้อมูลที่ซ้ำกันออกไป
5. จัดการกับข้อมูลผิดปกติ (Outliers)
- ตรวจหา Outliers: ใช้เทคนิคทางสถิติ เช่น Z-score, IQR เพื่อหาข้อมูลที่เบี่ยงเบนจากค่าอื่นๆ มาก
- จัดการ Outliers: ตัดสินใจว่าจะลบออก หรือปรับค่า
6. แปลงข้อมูล (Transformation)
- แปลงข้อมูลเชิงหมวดหมู่: แปลงข้อมูลที่เป็นข้อความให้เป็นตัวเลข (เช่น One-Hot Encoding)
- ปรับขนาดข้อมูล: ปรับขนาดข้อมูลให้มีช่วงค่าใกล้เคียงกัน (เช่น Normalization, Standardization)
7. ตรวจสอบความสมดุลของข้อมูล (Data Imbalance)
- ตรวจสอบสัดส่วน: ตรวจสอบว่าข้อมูลแต่ละคลาสมีความสมดุลกันหรือไม่
- แก้ไขปัญหา: ใช้เทคนิค Oversampling, Undersampling หรือ SMOTE เพื่อแก้ไขปัญหาข้อมูลไม่สมดุล
สรุป
การทำ Data Cleansing เป็นขั้นตอนที่สำคัญที่สุดขั้นหนึ่งในการสร้างโมเดล Machine Learning ที่มีประสิทธิภาพ การลงทุนเวลาในการทำความสะอาดข้อมูล จะช่วยให้เราได้โมเดลที่มีคุณภาพสูง และสามารถนำไปใช้ในการตัดสินใจทางธุรกิจได้อย่างมั่นใจ
หากธุรกิจของคุณ ต้องการทำ Data Cleansing อย่างถุกต้องและแม่นยำ เพื่อนำข้อมูลไปวิเคราะห์และใช้งานอย่างเต็มประสิทธิภาพ กรอกแบบฟอร์มข้างล่าง เพื่อปรึกษา Predictive โดยไม่มีค่าใช้จ่ายได้เลยค่ะ
อ่านเพิ่มเติม Case Study ของการทำ Data Cleansing
อ้างอิง 5 Data Cleaning Techniques for Better ML Models , Data Cleansing vs Data Cleaning
How we can help
Fill out the form below to discuss your needs or learn more about our services
"*" indicates required fields